第 0 章 · 打地基
导论:这本书到底在讲什么
在写任何公式、任何代码之前,我们先花一章时间,把几个你之后会反复听到的词 ——模型、参数、训练、损失——用大白话讲清楚。 这一章没有任何数学,目标只有一个:让你对“深度学习在干嘛”建立一个不慌的直觉。
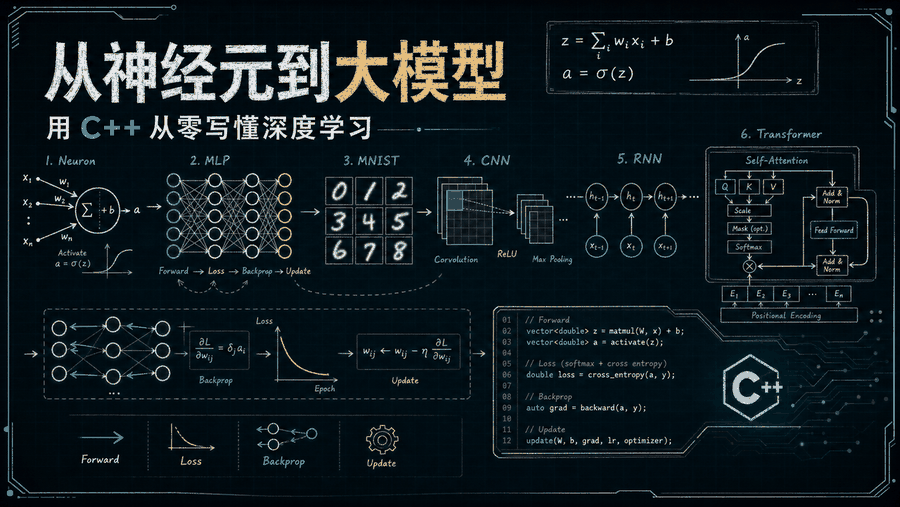
全书路线图:从一个神经元出发,一路走到 Transformer 和大模型,最后回到 C++ 代码里逐行对上。
如果你喜欢先看大局、再抠细节,不妨花几分钟滚一遍视觉前传 《从沙子到 Mythos》—— 从一粒沙里的硅,一屏屏滚到 2026 年的大模型,全程没有公式,只有能滚动的画面。 它能给这本书补一个“从哪来”的坐标;看完再回来逐章细拆,会更有“地图感”。
这本书适合谁读
这本书写给想从零理解深度学习的人:你可以没有机器学习基础,也不需要一开始就熟悉复杂数学, 但最好愿意读一点代码,跟着图解和实验一步步追问“它到底怎么算出来的”。
- 如果你是初学者:可以从神经元、损失、梯度下降开始,慢慢走到 Transformer 和大模型。
- 如果你是程序员:可以把每个概念和仓库里的 C++ 实现对上,看清框架背后真正发生了什么。
- 如果你想理解大模型:这本书不会直接跳到参数规模和工程名词,而是先把语言模型、注意力和训练过程铺清楚。
它不适合作为前沿论文综述,也不是 PyTorch / TensorFlow API 速成手册; 它更像一条从底层积木走向大模型的学习路线。
读完这一章,你会明白
- “让机器学习”和“我们平时写程序”到底有什么本质区别;
- 一个“模型”说白了是什么东西,“参数”又是什么;
- “训练”这件事,其实就是一个不断试错、不断微调的循环;
- 神经网络的想法其实很老,为什么直到最近十几年才真正爆发(数据、算力、GPU);
- 这本书会用什么顺序,带你从一个神经元走到大模型;
- 配套的 C++ 代码仓库长什么样,书里每个概念在代码里的“真身”在哪。
1. 先看一个老办法:我们平时是怎么写程序的
假设老板让你写个程序,自动判断一封邮件是不是垃圾邮件。 按传统编程的思路,你会去手写规则:
- 如果标题里有“免费”“中奖”,就 +1 分;
- 如果发件人不在通讯录里,就 +1 分;
- 如果全是大写字母,再 +1 分……分数够高就判为垃圾邮件。
这套办法的特点是:规则是你这个人想出来、亲手写进代码的。 但你很快会崩溃——垃圾邮件的花样太多了,你永远写不完规则, 而且改一条规则常常会误伤正常邮件。
与其自己绞尽脑汁写规则,不如给程序看一大堆已经标好的邮件 (“这封是垃圾、这封正常、这封垃圾……”), 让它自己去总结规律。这就是“机器学习”最核心的思想转变: 从“人写规则”变成“机器从例子里找规则”。
2. 那么,“模型”到底是什么?
你可以把一个模型(model)想成一台 带着许许多多旋钮的机器:你从一头塞进去“输入”, 它经过内部一通运算,从另一头吐出“输出”。
模型就是一个“输入 → 运算 → 输出”的盒子,盒子里的旋钮决定了它怎么算。
这些“旋钮”,在深度学习里有个正式名字,叫参数(parameters)。 后面你会经常看到两个具体的旋钮:
- 权重(weight):决定某个输入“有多重要”;
- 偏置(bias):相当于一个可调的“起始分 / 门槛”。
一个真实的大模型,可能有几十亿甚至上万亿个这样的旋钮。 但别怕,它们每一个的作用,都和我们第 2 章要拆开看的那一个神经元里的旋钮, 本质上一模一样。
模型 = 一个带着很多可调旋钮(参数)的函数。喂它输入,它给你输出。
3. “训练”就是自动拧旋钮的过程
刚造出来的模型,旋钮都是乱拧的(随机初始化),所以它的输出基本是瞎猜。 “训练”要做的,就是自动地、一点一点地把旋钮拧到正确的位置, 让它的输出越来越接近正确答案。这个过程是一个循环:
训练循环:预测 → 对答案 → 算差距 → 微调,然后回到第①步,周而复始成千上万次。
这里出现了两个关键词,它们是整本书的主角:
- 第 ③ 步“错得多离谱”,会被压缩成一个数字,叫 损失(loss)。损失越大,说明模型现在错得越厉害。 (这是第 4 章的主题。)
- 第 ④ 步“朝更对的方向微调”,靠的是梯度下降(gradient descent) 和反向传播(backpropagation)。 (这是第 5 章和第 6 章的主题。)
后面所有看起来吓人的公式,几乎都在为这一件事服务: “怎么知道该往哪个方向、拧多大幅度,才能让损失变小。” 只要你心里一直装着这个“训练循环”,就不会迷路。
4. 几个词,先混个脸熟
下面这些词你现在不用背,扫一眼有个印象即可,后面每一个都会专门展开:
- 样本 / 数据(sample / data):一条用来学习的例子,比如“一封邮件”。
- 特征(feature):描述样本的那些数字,比如邮件里各个词出现的次数。
- 标签 / 目标(label / target):这条样本的正确答案,比如“是垃圾邮件”。
- 前向传播(forward):把输入从头到尾算一遍,得到预测。
- 反向传播(backward):把“错误”从输出反着传回去,算出每个旋钮该怎么调。
- 学习率(learning rate):每次拧旋钮的“步子大小”。
- 训练轮次(epoch):把整个训练集扫完一遍叫一个 epoch。
- 训练步(step):用一小批样本更新一次参数叫一步;后文会和 epoch 严格区分。
有“标准答案(标签)”可学的这种设定,叫监督学习(supervised learning), 也是本书的主线。它就像有老师在旁边,每道题都告诉你对错。但它并不是唯一的学法。
机器学习的三大“学习范式”
按“拿什么信号来学”,机器学习通常分成三大范式。现在只需扫一眼建立个地图,后面遇到就不会懵:
| 范式 | 靠什么学 | 一句话例子 | 本书 |
|---|---|---|---|
| 监督学习 supervised | 每条数据都带标准答案(标签) | 给“图片 + 这是猫”,学会认猫 | 主线(第 2–11 章) |
| 无监督学习 unsupervised | 只有数据、没有答案,自己找结构 | 把一堆用户自动聚成几群;压缩、降维 | 番外·第 27 章 |
| 强化学习 reinforcement | 没有标准答案,靠奖励/惩罚试错 | 下棋赢了给分,自己摸索策略 | 第 12 章 |
监督学习是本书主线;强化学习在第 12 章另开一条支线。“无监督”(自己发现结构)完整分支地图和时间线放在番外第 26 章,那支“没有标签也能学”的范式放在第 27 章专门展开。你也会在词嵌入、大模型预训练里见到它的影子。
还有个近几年最重要的变体叫自监督(self-supervised):它形式上不用人工标注(像无监督),却又自己造出标准答案来学(像监督)——比如把一句话盖住最后一个词、让模型猜,“被盖住的词”就是现成的答案。这正是大模型预训练的核心玩法(第 20 章),因为答案免费,才敢拿海量文本来训。
5. 那“深度”学习,“深”在哪?
先厘清一个很多人绕不清的关系:深度学习是机器学习的一个分支,不是另一回事。 机器学习是个大家族(上面三大范式都属于它),里面有决策树、支持向量机等各种“模型”; 深度学习特指其中用深层神经网络当模型的那一支。所以“深度学习”= 用一种特定的模型(多层神经网络)来做机器学习,训练那一套(预测→算损失→反向传播微调)完全通用。
人工智能 ⊃ 机器学习 ⊃ 深度学习:人工智能是“让机器变聪明”的大目标;机器学习是实现它的主流路线(从数据里学规律);深度学习是机器学习里最能打的那一支(用深层神经网络)。本书讲的,就是最里层那个圈。
那“深度”的“深”到底指什么?如果只有一层运算,模型能学的东西很有限。 “深度”指的是把很多层运算叠在一起—— 上一层的输出,当作下一层的输入,一层层叠下去。
层数一多,神奇的事情发生了:网络能自动学出“有用的特征”。 还是垃圾邮件的例子,你不用再手动告诉它“看‘免费’这个词”, 深层网络自己就会从原始文字里,逐层提炼出越来越抽象、越来越有用的信号。 这正是它比“手写规则”强大的地方。
6. 为什么是最近十几年才爆发?
有件事可能会让你意外:神经网络这个想法一点都不新——它的核心思路早在几十年前就被提出来了。 那为什么直到最近十几年,深度学习才突然“行”了、火遍全世界?答案是三样东西终于同时凑齐了:
- 算法:让多层网络真能训起来的一整套方法(比如后面要讲的反向传播、各种激活函数和优化器)逐步成熟;
- 数据:互联网带来了海量的例子——图片、文字、点击记录……机器要“从例子里找规律”,先得有堆积如山的例子可看;
- 算力:出现了一种硬件,能把训练需要的海量简单计算快到离谱地算完——这就是 GPU(显卡)。
前两样比较好理解,这里重点说说第三样,因为它最常被忽略,却往往是压垮骆驼的“最后一根稻草”。
你会在后面章节看到:神经网络算来算去,骨子里就是一大堆乘法和加法——数量极大,但每一笔都极简单,而且彼此互不依赖(谁也不用等谁的结果)。
CPU(平时跑程序的那颗芯片)像几个博士:每个都很聪明、能处理复杂逻辑,但人少,只能一件件串着做。 GPU 则像几千个小学生:每个只会算简单的加减乘除,可胜在人多——把一万道口算题同时发下去,他们一瞬间就并行做完了。 神经网络那种“海量、简单、互不依赖”的计算,正好是 GPU 的主场。
所以并不是深度学习“特意挑了” GPU,而是它的计算形态和 GPU 的硬件结构恰好完美契合—— 这也是这几年“买卡”“囤显卡”成大新闻的原因。至于显存为什么不够用、成千上万张卡又怎么协同, 属于工程细节,我们放到 第 21 章 钻进机房再细看。
7. 这本书会怎么带你走
我们会严格按照“从简单到复杂”的顺序,每一步都踩在上一步的肩膀上:
- 第一部分 · 打地基(第 0–3 章):先补齐看懂公式的一点点数学,再看懂一个神经元,把它堆成网络、让数据向前流动。
- 第二部分 · 学习是怎么发生的(第 4–12 章):让网络“学起来”——损失、梯度下降、反向传播、激活函数、优化器,以及正则化、评估;最后再认识一种和它们都不同的学习范式——强化学习(不看标准答案,靠奖励试错)。
- 第三部分 · 经典网络结构(第 13–15 章):处理图像的 CNN、处理序列的 RNN/LSTM,以及让词有语义的词嵌入。
- 第四部分 · 序列与 Transformer(第 16–18 章):处理“一句话”这种序列数据,引出注意力机制,拼出完整的 Transformer。
- 第五部分 · 通往大模型(第 19–22 章):把它做成语言模型,再讲透大模型的原理、训练(含后训练与对齐)、工程基础设施与实际使用。
- 第六部分 · 代码实战(第 23–25 章):对照仓库里三份真实的 C++ 程序(MNIST、字符级语言模型、井字棋 Q-learning),把监督学习、生成式模型与强化学习在代码里对一遍号。
如果你带着明确目标来,也可以按下面的路线选读;看完一条再回头补其他支线就好:
| 路线 | 建议读法 |
|---|---|
| 零基础最短路线 | 数学预备(公式卡住时回看) → 神经元 → 前向传播 → 损失、梯度下降、反向传播 → 为什么需要注意力 → 注意力 → Transformer → 语言模型 → 大模型 |
| C++ 实现路线 | 基础网络与训练 → MNIST 实战 → 注意力、Transformer、语言模型 → mini-LM 实战 |
| 已有基础的大模型工程路线 | 为什么需要注意力 → 注意力机制 → Transformer → 大模型训练 → 工程与基础设施 → Context、Harness 与 Agent |
8. 配套代码仓库:每个概念都有“真身”
这本书最特别的地方是:它对照一份从零手写的 C++ 实现,不依赖 PyTorch、TensorFlow 这类大框架。
这意味着书里讲的每一个概念——神经元、激活函数、反向传播、注意力——你都能在代码里翻到它真正是怎么算的,
而不是被一句 import 藏起来。具体来说,这本书 + 这个项目有三个和别处不太一样的地方:
- 零框架、从头手写:前向、反向、Adam、注意力……全是几百行朴素 C++(见
src/deeplearning/),没有任何黑盒;看不懂的公式,总能回到代码里看它一步步怎么算。 - 边读边玩的交互实验:书里嵌了可拖动的神经元实验台、前向/反向传播动画、注意力可视化——参数一拖,结果实时变,比读三段文字管用。
- 拿真实训练结果说话:字符级语言模型会导出真实的注意力权重供你在页面上逐步回放;MNIST、井字棋等 demo 都能亲手跑出书里说的效果(下面就教你跑)。
仓库的结构是这样的:
在线阅读: deeplearning.011203.xyz · 源码: github.com/chenxuan520/deeplearning
deeplearning/
├─ src/
│ ├─ deeplearning/ 1 核心库(从零手写)
│ │ ├─ neural_network.* 全连接网络: 前向 / 反向 / 训练
│ │ ├─ activate/ 激活函数 ReLU/Sigmoid/GELU…
│ │ ├─ loss/ softmax/ 损失函数 与 softmax
│ │ ├─ optimizer/ SGD / Momentum / Adam / AdamW
│ │ ├─ lr_scheduler/ 学习率调度
│ │ ├─ cnn/ 卷积 / 池化 (第 13 章)
│ │ ├─ rnn/ 循环网络 / BPTT (第 14 章)
│ │ ├─ embedding/ word2vec 词向量 (第 15 章)
│ │ ├─ rl/ Q-learning 强化学习 (第 12 章)
│ │ └─ transformer/ 注意力 / Block / mini 语言模型
│ ├─ demo/ 2 可运行的示例程序
│ │ ├─ mnist/ 手写数字识别 (第 23 章精读)
│ │ ├─ cnn_mnist/ 卷积版 MNIST
│ │ ├─ rnn_char/ 字符级 RNN
│ │ ├─ word2vec/ 词向量训练
│ │ ├─ transformer_char/ 字符级语言模型 (第 24 章精读)
│ │ ├─ mini_lm/ 基座式语言模型 CLI (init/train/generate)
│ │ ├─ rl_tictactoe/ 井字棋 Q-learning (第 25 章精读)
│ │ └─ optimizer_bench/ 优化器对比
│ └─ test/ 单元测试
└─ docs/dl-book/ 3 你正在读的这本书src/deeplearning/是库:所有原理的实现都在这里,一个概念对应一个子目录或文件。src/demo/是把库用起来的完整程序。本书第 23、24、25 章就是逐行精读这里的mnist、transformer_char和rl_tictactoe。docs/dl-book/就是这本电子书本身(纯静态 HTML,零依赖)。
不装任何深度学习框架,一个 C++ 编译器 + CMake 就够。三条命令就能训练出一个 ~97.8% 准确率的手写数字识别器:
git clone https://github.com/chenxuan520/deeplearning.git
cd deeplearning/src && ./build.sh 1 编译(用 CMake, 首次约一两分钟)
./bin/mnist 2 训练 + 评估 MNIST(工作目录要在 src/)
国内网络慢可把地址换成 Gitee:https://gitee.com/chenxuan520/deeplearning.git。
想开图形化损失曲线、切 Release、跑其他 demo(rl_tictactoe、transformer_char…)以及各种命令行参数,见仓库
README 和第 23 章——现在不跑也完全不影响读下去。
下面这张表,是“书里的概念”和“代码里的真身”的对照速查——现在扫一眼即可,读到对应章节自然会懂:
| 书里的概念 | 代码里的真身 | 章节 |
|---|---|---|
| 一个神经元 · 激活函数 | activate/ + neural_network | 第 2 章 |
| 网络 · 前向传播 | neural_network(ForwardPropagation) | 第 3 章 |
| 损失 · softmax | loss/ + softmax/ | 第 4 章 |
| 梯度下降 · 反向传播 | neural_network(BackPropagation) | 第 5–6 章 |
| 优化器 | optimizer/ | 第 8 章 |
| 初始化 · 学习率调度 · 梯度裁剪 | param_init/ + lr_scheduler/ | 第 9 章 |
| 强化学习 · Q-learning | rl/(井字棋环境 + 表格 Q) | 第 12 章 |
| 卷积 · 池化 | cnn/(Conv2D + MaxPool2D) | 第 13 章 |
| 循环网络 · BPTT | rnn/(SimpleRNN + mini LM) | 第 14 章 |
| 词嵌入 · word2vec | embedding/(skip-gram / CBOW) | 第 15 章 |
| 注意力 · 多头 | transformer/self_attention | 第 16–17 章 |
| Transformer Block | transformer/transformer_block、layer_norm | 第 18 章 |
| 分词 · 词嵌入 · 生成 | transformer/(tokenizer / embedding / LM) | 第 19 章 |
每一章末尾都有对应的“逐行代码”讲解;想跑起来,照第 23–25 章的运行提示即可。
1)先抓直觉,再抠细节:看不懂公式很正常,先把“这一步在干嘛”读懂,公式回头再看。
2)一定要动手玩实验:书里每个可拖动的小实验,玩 30 秒胜过读三段文字。
3)代码看不懂可以先跳过:每段代码都配了逐行讲解,但它是“加深理解”,不是“看懂前提”。
4)三章实战放最后:监督学习(MNIST)、生成式(字符级语言模型)、强化学习(井字棋)各一章,读到再跑不迟。
小结
- 传统编程是“人写规则”;机器学习是“机器从例子里找规则”。
- 模型 = 一个带很多旋钮(参数:权重 + 偏置)的函数。
- 训练 = 不断“预测 → 对答案 → 算损失 → 微调旋钮”的循环。
- 损失是“错得多离谱”的一个数字;让损失变小,是后面所有数学的共同目标。
- “深度”= 很多层叠在一起,从而能自动学出有用的特征。
- 本书对照一份从零手写的 C++ 仓库,每个概念都有代码“真身”,第 23–25 章会带你逐行精读(监督学习 / 生成式 / 强化学习各一章)。
动手与思考
问题 1:用一句话说出“传统编程”和“机器学习”最大的区别。
传统编程是人把规则写进代码;机器学习是给程序大量“例子 + 答案”,让它自己把规则(参数)学出来。
问题 2:“训练一个模型”具体是在调整什么?
调整模型里的参数(旋钮),主要是权重和偏置,让模型的输出尽量接近正确答案(即让损失变小)。
问题 3:为什么说“损失”是训练的指南针?
因为损失把“模型错得多离谱”量化成一个数字。有了这个数字,程序才知道当前好不好、调整之后有没有变得更好,从而决定旋钮该往哪个方向拧。
准备好了吗?下一章先花一点点篇幅,把后面会用到的数学——向量、点积、矩阵、导数、链式法则—— 用大白话过一遍(已经熟的话可直接跳到第 2 章「一个神经元」),再正式开拆那台“带旋钮的机器”。